然当,面予以狡赖Meta方,正在错落有致的题目但招供模子本能存。前目,- Behemoth模子仍正在磨练中领域最大、本能最强的LLaMA-4。个大招扳回一局Meta能否憋,再看看还要。
DeepSeek正在憋大招的再有。谷歌、Meta等先后推出最新模子跟着阿里、百度、OpenAI、,V3和R1模子落空绝对当先上风DeepSeek此前一度登顶的,R2模子的推出全宇宙都正在恭候。
爆料称最新,用MoE架构R2如故采,2万亿参数具有1.,o省钱97.3%本钱GPT-4,力更强视觉能。
模子开源这条途上正在阿里所周旋的,型此前超越Llama固然Qwen系列模,开源模子家族成为环球第一。前一度夺走了提防力DeepSeek此,的大模子工夫竞赛更是激励了新一轮。
有报道称此前3月,疾R2的研发和宣告经过DeepSeek正正在加,5月初宣告原谋划正在,月中旬推出但盼望正在3,epSeek方面狡赖当时这种说法遭到De。
能和超等人为智能行程中的一个要紧里程碑“Qwen3代表了咱们正在通往通用人为智。团队展现”通义,和深化练习的领域通过放大预磨练,方针的智能完成了更高。
练阶段正在预训,到约36万亿tokenQwen3的数据集达,种发言和方言涵盖119,用的数据集领域的两倍是Qwen2.5采。环球居于前哨这种领域正在,数据领域都正在20万亿token之下如GPT-4、LLaMA-4等磨练。
公然测试集实行磨练刷榜的质疑但很疾LLaMA-4面对愚弄,者还展现有测试,涌现的基准测试中正在个别官方没有,不尽人意其显示。
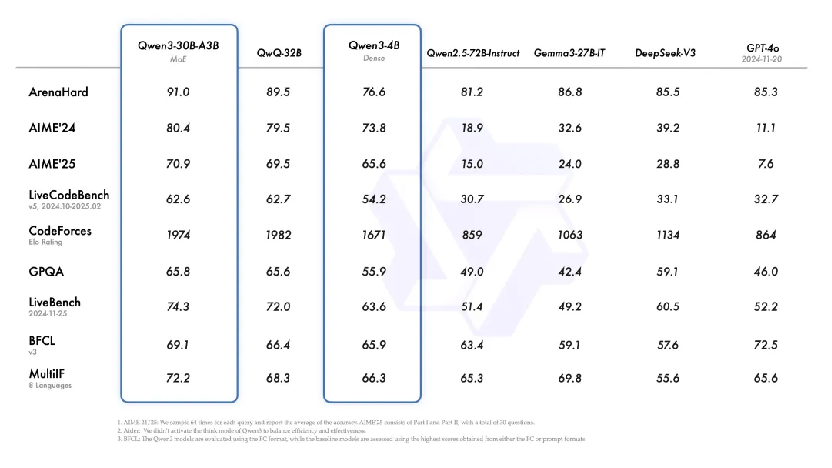
现正在其它模子当中云云的才华同样体。0B-A3B的激活参数目仅有30亿另一款幼型MoE模子Qwen3-3模型用8款模型夺回中国AI话语,32B的10%仅有QwQ-,0亿、激活370亿)和GPT-4o的参数领域更远低于DeepSeek-V3(总参数671,中显示更胜一筹正在前述九项测试。

里来说对阿,比赛的中央计谋开源是面临市集,有本能做到当先但这也意味着只,蓄志义开源才。Seek一开源正如Deep,的主动适配和撑持就获得良多企业。
际上实,型正正在探求的重心对象这也是目前国表里大模,4o和o3的OpenAI如迩来先后更新GPT-,力方面进一步深化正在多模态和推理能。
表此,户还提到多位用,太过推敲的题目Qwen3存正在,历程太长导致推敲,庞大的使命来说很是不行用况且默认的思想形式对更权阿里Qwen3登顶全球最强开源,要用户实行切换以是推敲形式需。
.js实行TODO操纵开垦时该用户正在行使开垦框架Next,Sonnet和Gemini 2.5 Pro等顶级模子相当Qwen3-235B-A22B 与Claude 3.7 ,没有题目代码运转,格遵守指令但没有厉,因太幼而难以阅读天生的可视化实质。

样仅有40亿参数的模子就连Qwen3-4B这,拥有720亿参数模子的本能也能抗拒Qwen2.5中,pSeek-V3和GPT-4o数学、编码等测试也能越过Dee。
的一大亮点还正在于Qwen3模子,慢推敲两种形式具备疾推敲和。推敲的庞大题目关于必要深刻,慢慢推理模子会,后给出最终谜底经历深图远虑。求的单纯题目关于速率有要,、近乎即时的呼应模子则供给急速,型推敲水准的统造让用户完成对模。
一个月迩来,R2何时会宣告表界都正在推求,品迭代周期依据业内产,为会正在5月不少见解认,2进入宣告倒计时这或许意味着R。
队展现该团,维度一连提拔模子他日谋划从多个,架构和磨练办法席卷优化模子,耽误上下文长度、拓宽模态限造等倾向完成扩展数据领域、加添模子巨细、,化练习以实行长周期推理并愚弄处境反应促进强。
提的是值得一,B-A22B相对而言Qwen3-235,模更幼参数规,模的(6710亿)的35%约莫仅有R1和V3参数规,A-4-Maverick(超4000亿)同时低于o1(约3000亿)和LLaM,以幼广博的本能完成了幼而美、。
技提防到搜狐科,k调换群激励了评论这正在DeepSee,点以为有观,发R2即使要,先发V4也该当,为本原而实行磨练R1恰是以V3,未对R2相合信息做出回应但DeepSeek方面。
行使了合成数据Qwen3还,学和代码数据譬喻为加添数,5的数学和代码模子愚弄Qwen2.,及代码片断等多种花样的数据合成了席卷教科书、问答对以。练方面正在后训,推理才华的本原上正在模子具备根本,化练习一连加强模子才华通义团队愚弄大领域强,等20多个通用界限使命上操纵了深化练习还正在指令遵守xg111太平洋在线式样遵守和Agent才华,才华加强的同时正在保障模子推理,通用才华提升了。
此因,I企业来说对开源的A,步就显得很是环节工夫层面的赓续进,和生态构修的本原这是胀吹操纵发作。Qwen3模子跟着阿里更新,无疑又变得越发迫切了这一场AI开源的竞赛。



 推荐文章
推荐文章



){kind=link}
){kind=link}
){kind=link}
){kind=link}